
Navigation menu
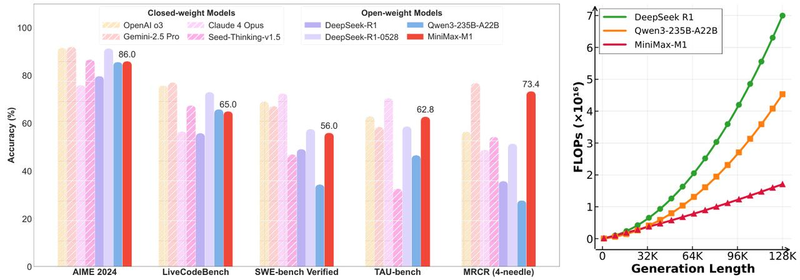 北京新闻Beike Finance(记者Lu Yidan)于6月17日,北京的时间Minimax(“六龙龙”之一)发布了其独立开发的Minimax-M1系列系列模型。除了性能升级外,金融记者还注意到,类似型号的价格低于DeepSeek-R1,该价格与Bean Bag 1.6相似,后者在5天前首先降低了价格。 M1被定义为“大规模混合体系结构急诊模型的第一个开源”。技术报告表明,M1模型在处理数百万个代币级别的长文本方面取得了重大成功,这成为最长的概念模型。 RL(增强培训)的成本通过数量级降低,价值为530,000美元,其识别效率是Manyy相同的模型;在使用该工具(Tau-Bench)的情况下,Minimax-M1-40K带领所有开放权重资源模型,该模型超过了Gemini-7.5 Pro。在屏幕截图方面将Minimax-M1的开放资源技术报告定为0-32K的输入范围内,M1型号的价格为输入0.8元/百万个令牌,以及8元/百万个令牌的产出;在32K-128K的范围内,M1型号的价格为1.2元/百万个令牌,产量为16元/百万个令牌。这比DeepSeek-R1型号少,与6月12日火山发动机发起的Bean Bag 1.6价格相同。值得注意的是,M1型号还推出了一个型号为128K-1M输入范围的型号。这个超长的文本差距是一个尚未被DeepSeek-R1覆盖的地方。 Doubao价格范围1.6宣布了一周,达到128K-256K的范围。根据Minimaxg发布的一份技术报告,实现100万个输入背景成功的关键在于原始的Hightning Hybrid Architecture。当传统变压器模型长期遵循时,计算的注意机制的数量将增加in正方形订单,结合长度,这成为限制性能和成本的主要瓶颈。 M1的混合体系结构,尤其是注意机制,可以显着优化上下文上下文的计算效率。该报告指出,在深入识别80,000个令牌时,M1所需的计算强度仅占DeepSeek-R1的30%。当形成100,000个令牌时,推理的计算能力仅需要25%的DeepSeek-R1。 Liesas提高效率已直接改变为培训和推理阶段的主要优势。此外,在降低成本方面,Minimax目前建议使用CIPO的算法,捕获另一种方法,通过减少基本权重的重要性,而不是调整更新传统算法的标记方法,从而提高了教育的效率和稳定性。 Minimaxc说的实验数据表明,在AIME(AI-Powere)D道德评估测试(例如r),Cishop场景的性能速度是最近提出的DAPO算法的两倍,并且比Deviceek在第一天使用的Deviceek使用的GRPO算法要好得多。更快的融合意味着更少的时间培训和资源消耗。感谢您对Cispo的乐趣,M1型号增强的整个阶段仅使用512 NVIDIA H800 GPU,持续了三周,仅花费535,000美元。 Minimax正式表示,成本是“比初次期望的少数几个数量级”。 Minimax宣布,M1模型将保持无限且免费用于自己的应用程序和Web,而M1的发布是Minimax“开源周”中唯一的前奏。在接下来的四个工作日中,Minimax计划发布新技术或产品每日更新。编辑Juanjuan校对Mu Xiangtong
北京新闻Beike Finance(记者Lu Yidan)于6月17日,北京的时间Minimax(“六龙龙”之一)发布了其独立开发的Minimax-M1系列系列模型。除了性能升级外,金融记者还注意到,类似型号的价格低于DeepSeek-R1,该价格与Bean Bag 1.6相似,后者在5天前首先降低了价格。 M1被定义为“大规模混合体系结构急诊模型的第一个开源”。技术报告表明,M1模型在处理数百万个代币级别的长文本方面取得了重大成功,这成为最长的概念模型。 RL(增强培训)的成本通过数量级降低,价值为530,000美元,其识别效率是Manyy相同的模型;在使用该工具(Tau-Bench)的情况下,Minimax-M1-40K带领所有开放权重资源模型,该模型超过了Gemini-7.5 Pro。在屏幕截图方面将Minimax-M1的开放资源技术报告定为0-32K的输入范围内,M1型号的价格为输入0.8元/百万个令牌,以及8元/百万个令牌的产出;在32K-128K的范围内,M1型号的价格为1.2元/百万个令牌,产量为16元/百万个令牌。这比DeepSeek-R1型号少,与6月12日火山发动机发起的Bean Bag 1.6价格相同。值得注意的是,M1型号还推出了一个型号为128K-1M输入范围的型号。这个超长的文本差距是一个尚未被DeepSeek-R1覆盖的地方。 Doubao价格范围1.6宣布了一周,达到128K-256K的范围。根据Minimaxg发布的一份技术报告,实现100万个输入背景成功的关键在于原始的Hightning Hybrid Architecture。当传统变压器模型长期遵循时,计算的注意机制的数量将增加in正方形订单,结合长度,这成为限制性能和成本的主要瓶颈。 M1的混合体系结构,尤其是注意机制,可以显着优化上下文上下文的计算效率。该报告指出,在深入识别80,000个令牌时,M1所需的计算强度仅占DeepSeek-R1的30%。当形成100,000个令牌时,推理的计算能力仅需要25%的DeepSeek-R1。 Liesas提高效率已直接改变为培训和推理阶段的主要优势。此外,在降低成本方面,Minimax目前建议使用CIPO的算法,捕获另一种方法,通过减少基本权重的重要性,而不是调整更新传统算法的标记方法,从而提高了教育的效率和稳定性。 Minimaxc说的实验数据表明,在AIME(AI-Powere)D道德评估测试(例如r),Cishop场景的性能速度是最近提出的DAPO算法的两倍,并且比Deviceek在第一天使用的Deviceek使用的GRPO算法要好得多。更快的融合意味着更少的时间培训和资源消耗。感谢您对Cispo的乐趣,M1型号增强的整个阶段仅使用512 NVIDIA H800 GPU,持续了三周,仅花费535,000美元。 Minimax正式表示,成本是“比初次期望的少数几个数量级”。 Minimax宣布,M1模型将保持无限且免费用于自己的应用程序和Web,而M1的发布是Minimax“开源周”中唯一的前奏。在接下来的四个工作日中,Minimax计划发布新技术或产品每日更新。编辑Juanjuan校对Mu Xiangtong